Dinos cómo podemos ayudarte
Ventas y precios
Habla con un representante sobre las necesidades de tu empresa
Ayuda y soporte
Consulta nuestras opciones de soporte de productos
Consultas generales y ubicaciones
Contáctanos
Explicación de DataOps
Entiende cómo DataOps aprovecha la analítica para generar insights empresariales accionables
¿Qué es DataOps?
DataOps, abreviatura de operaciones de datos, están una práctica que aplica las mejores prácticas de ingeniería ágil y DevOps en el campo de la gestión de datos para organizar, analizar y aprovechar mejor los datos y así desbloquear el valor empresarial. Es una colaboración entre equipos de DevOps, ingenieros de datos, científicos de datos y equipos de análisis para acelerar la recopilación e implementación de insights empresariales orientados a datos.
El éxito de DataOps están centrales la automatización y orquestación de las canalizaciones de datos. Los esfuerzos manuales por sí solos no pueden seguir el ritmo de la cantidad de datos generados. La automatización y la orquestación Permite:

Movimiento rápido y eficiente de datos entre varios sistemas

Optimización de la salud y el rendimiento de la cadena de datos
Controladores para DataOps
Muchas empresas tienen dificultades para organizar y aprovechar sus datos para Crea valor. He aquí por qué:
 |
Fuentes de datos en rápido aumento, debido a nuevos tipos de datos o modelos de negocio más complejos, que Haz difícil simplificar |
 |
Colaboración y participación empresarial insuficientes que no impulsan un cambio cultural exitoso |
 |
Enfoque poco claro para medir el éxito, especialmente en iniciativas fundamentales, ya que se observan muchos beneficios en el rendimiento de sons otros equipos |
 |
Desajuste de procesos, en el que los procesos y prácticas tradicionales de gestión de datos no se alinean bien con técnicas más recientes como la inteligencia artificial (IA) |
 |
Desafíos para operacionalizar a gran escala con expectativas crecientes de los interesados sobre la velocidad, flexibilidad, puntualidad y personalización de nuevas capacidades |
Objetivos de DataOps
Utilizar los datos correctamente puede mejorar e incluso revolucionar la forma en que operan las organizaciones. Pero, desafortunadamente, el 88% de los datos no se analizan y solo el 15% de los proyectos de big data Haz a producción. DataOps pretende resolver estos problemas cambiando la forma en que los equipos colaboran en torno a los datos y cómo se están implementados en la acción.
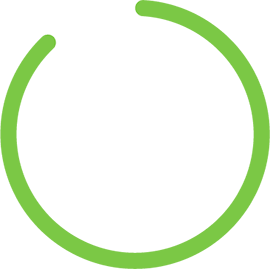
Hasta el 88% de los datos no se analizan
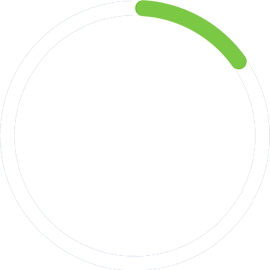
Solo el 15% de los proyectos de big data Haz a producción
Cómo funciona DataOps
El núcleo de DataOps está en aprovechar datos de calidad. Cuando las empresas logran esto con éxito, los equipos y líderes pueden ofrecer mayor valor y gestionar los riesgos presentes y futuros con más confianza. Las iniciativas exitosas de DataOps requieren lo siguiente:
Automatización

Comunicación y colaboración

Cultura

Automatización
Comunicación y colaboración
Cultura
El enfoque de BMC hacia DataOps
En BMC, sabemos que el panorama empresarial moderno presenta a equipos y líderes una lista creciente de desafíos y problemas que resolver. Aprender a aprovechar tus datos está fundamental para evolucionar y mantenerte competitivo en un mundo en constante cambio y disruptivo.
Como líderes del sector en orquestación de datos, contamos con una amplia trayectoria capacitando a empresas para convertirse en un negocio orientado a datos. Nuestras soluciones son diseñadas para soportar los entornos complejos que abarcan todo tu ecosistema—desde la nube hasta los centros de datos on-premises, pasando por el edge y todo lo que hay entre medias.
BMC aporta un valor único a DataOps mediante:
- Ofrecer orquestación a escala empresarial de data Pipelines
- Proporcionar visibilidad de extremo a extremo y acuerdos predictivos de nivel de servicio (SLA) en cualquier tecnología de datos o infraestructura
- Hacer cumplir las normas de gobernanza y cumplimiento en producción, asegurando al mismo tiempo una experiencia sin fricciones para los usuarios técnicos
Con soluciones de cartera como Control-M, Control-M Python Client y BMC AMI Data, te puedes simplificar incluso los Pipelines de datos más complejos, Permite a los científicos de datos Crea mejores flujos de trabajo y aprovechar tus datos a su favor Máximo potencial.